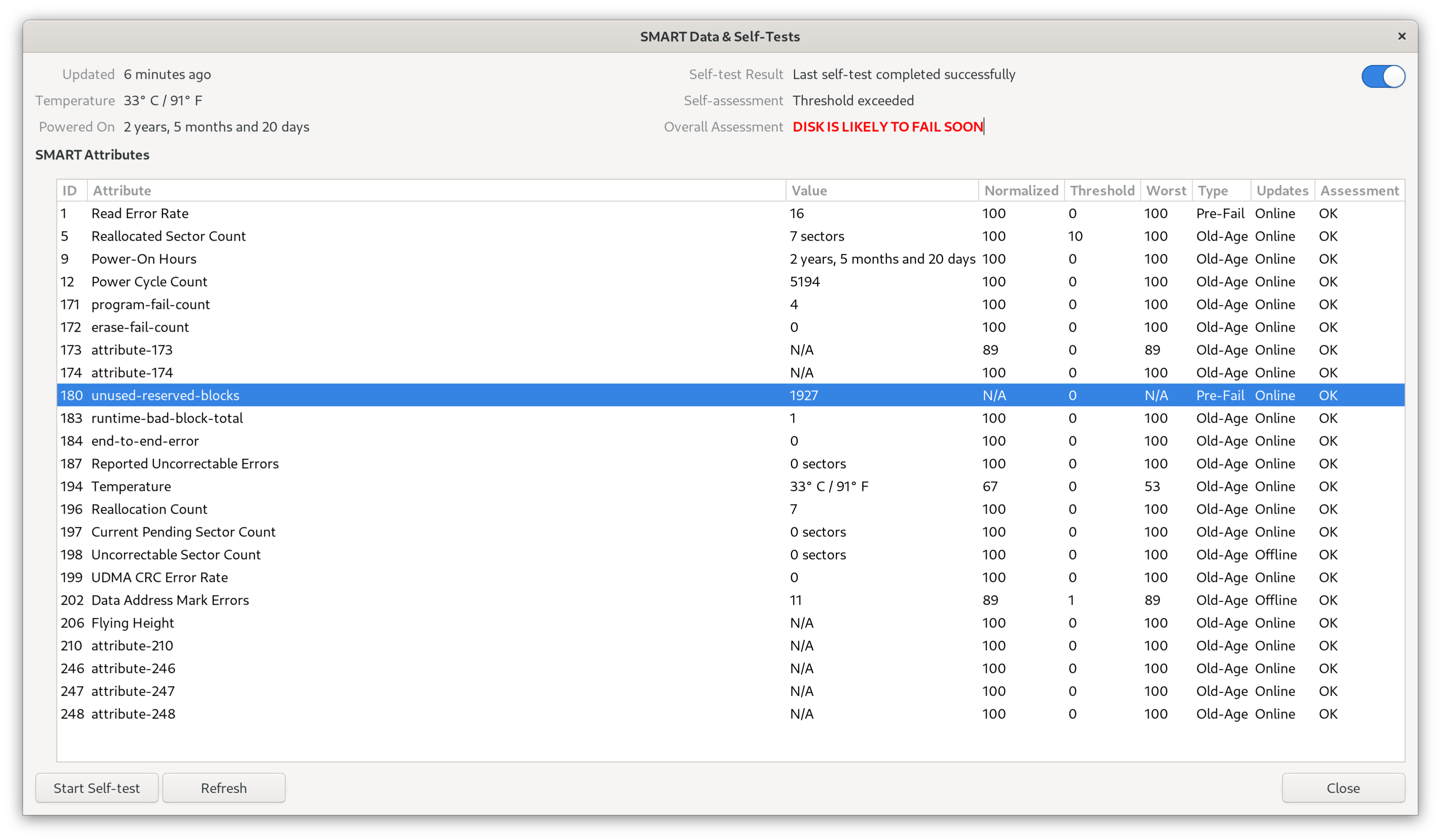
Not sure if it’s a bug that it now shows “might fail soon” warnings when the disk is actually OK, or if that warning should have been shown all along and the fact that it wasn’t was a bug that is now fixed.
Even then, I do find it strange that at least dozens of people (looking at this thread, bugzilla, the udisks2 bodhi update, and reddit) started getting the “DISK LIKELY TO FAIL SOON” warning only after a recent update, even though SMART self-tests seem to indicate everything is still OK or at least within thresholds.
That removed patch seems to have been specifically designed to prevent reporting of failure warnings by libatasmart which (in the patch author’s opinion) were overly sensitive:
The libatasmart attribute overall status differs slightly from
the drive SMART self-assessment and is very sensitive for particular
status values. Such status should fit more like a pre-fail warning,
no reason to fail hard the global assessment. Even a single reallocated
sector would cause a warning, while the drive could be quite healthy
otherwise.
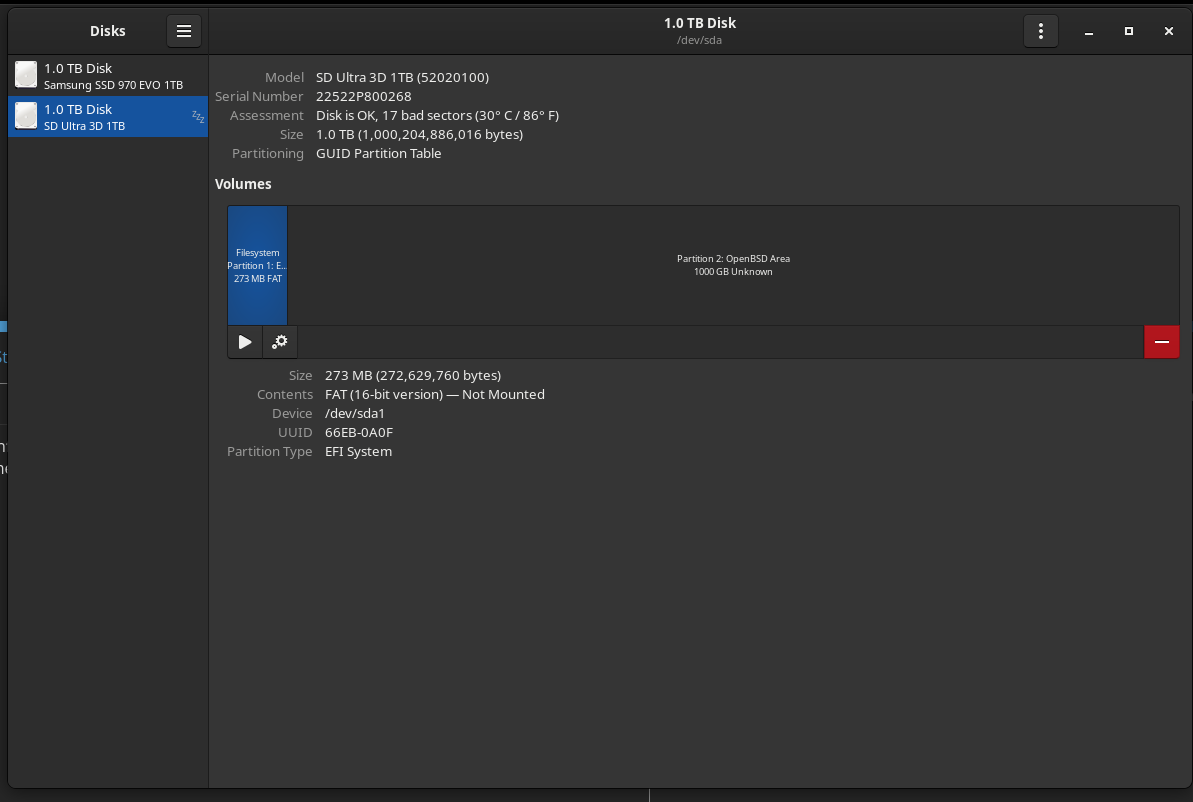
If “even a single reallocated sector” can cause a warning in the absence of the patch, it would explain why the disks in the screenshots in this thread (@janvlug 's with 7 reallocated sectors and @passthejoe 's with 17) started to report imminent failure with the latest (unpatched) libblockdev, where they hadn’t done so with the previous patched version.
I have 3 crucial micron and the last number, 11 here, indicates % of life used so far, not remaining. In other words, it increases starting from 0. Therefore, 89% life remaining. Maybe it’s particular to crucial, I don’t know, but I can assure you it’s meant to increase, not decrease. Here’s my new ssd data:
So what you’re saying is either there is a miscommunication somewhere in the stack concerning the intent of the field, or somehow crucial has created Benjamin Button drives, drives that age backwards in time.
Wow, it’s like new. My Win ssd, around 6 years old is at 83% and my Fedora ssd, purchased in oct 2023 is at 80% (it ages faster due to bi-yearly upgrades since F38)
This one isn’t my OS drive but it’s had a decent amount of data written to it.
So if I trust the data and assume that 0 is valid to the nearest integer percentage, then the drive could have gone through up to 0.5% of its life… it should last another 597 years!!
In fact I’ve been using realatime. It seems to be the Fedora default, correct me if I’m wrong.
For the LUKS btrfs partition → btrfs rw,relatime,compress=zstd:1,ssd,discard=async,space_cache=v2,commit=300,subvolid=405,subvol=/root
For the boot → ext4 rw,relatime
What didn’t help is when I restored from backup using dd because of LUKS. I stopped doing that and now use partclone.btrfs since I learned about it. But I had several full ssd dd restore to my account due fo failed upgrades or snatshots that went wrong prior to that.
I use commit=300 because this PC is immune to power failure.
Here’s what Grok has to say about realatime vs atime, if that info could be trusted →
atime vs. relatime
atime (Access Time)
Definition: Updates the access time (last read time) of a file or directory every time it is accessed (e.g., read, executed).
Mount Option: Enabled by default or explicitly set with atime.
Impact on SSD Longevity: Increases write operations because each file access updates the inode on disk, leading to more wear on SSDs.
Use Case: Useful for tracking file access (e.g., auditing, backups), but rarely needed in modern systems.
Definition: Updates the access time only if the previous atime is older than the modification time (mtime) or if the file hasn’t been accessed in at least 24 hours (or the mount time). It’s a compromise between atime and noatime.
Mount Option: Default on most modern Linux distributions (including Fedora 42) unless overridden.
Impact on SSD Longevity: Significantly reduces write operations compared to atime, as it avoids frequent updates, making it SSD-friendly.
Use Case: Balances access tracking with performance, suitable for most general-purpose systems.
Performance: Lower I/O overhead than atime, improving longevity and efficiency.
Comparison
Feature
atime
relatime
Access Update
Every read
Only if older than mtime or 24h
SSD Wear
Higher
Lower
Performance
Slower due to more I/O
Faster, less I/O
Use Case
Auditing, specific apps
General use, defaults
Default
Rarely used now
Common default
Recommendation
Use relatime for SSDs (and most systems) to minimize wear while retaining some access tracking.
Switch to noatime if you don’t need access time at all, offering the best longevity (e.g., for servers or read-heavy workloads).
Avoid atime on SSDs unless required for specific compliance or debugging purposes.