I have a very severe problem regarding total corruption of the root partition of my Fedora installation: the partition refuses to mount, resulting in an Emergency mode boot. I cannot provide a screenshot now, but at the end of journalctl, there are several errors saying that the partition tree is corrupt. The problem happened when I was benchmarking some ddr3 ram on an old pc. (so at first I thought it was a ram problem). Some recovery programs can recover about 6gb of data, but none of that data is what I want (my family photos and 200k*200k pixel fractals I generated, takes 30h to generate). The btrfs check error is very similar than the journalctl error:
Opening filesystem to check...
checksum verify failed on 118456320 found 000000B2 wanted FFFFFFAA
checksum verify failed on 118456320 found 000000B2 wanted FFFFFFAA
checksum verify failed on 118456320 found 000000B2 wanted FFFFFFAA
bad tree block 118456320, bytenr mismatch, want=118456320, have=6368586077744892065
ERROR: failed to read block groups: Input/output error
ERROR: cannot open file system
Trying to mount the partition makes that prompt appear:
I tried to use btrfs check --repair (I know it was very unwise of me) and got the same error as with the last command.
All partitionning tools list the partition as “HEALTHY” (LOL)
For further details, here is the result of lsblk:
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
loop0 7:0 0 2.2G 1 loop /rofs
sda 8:0 0 472G 0 disk
├─sda1 8:1 0 576M 0 part
├─sda2 8:2 0 1G 0 part
├─sda3 8:3 0 461.9G 0 part
└─sda4 8:4 0 8.5G 0 part [SWAP]
sdb 8:16 1 28.7G 0 disk
├─sdb1 8:17 1 2.4G 0 part /cdrom
├─sdb2 8:18 1 4.2M 0 part
└─sdb3 8:19 1 26.3G 0 part /var/crash
nvme0n1 259:0 0 238.5G 0 disk
├─nvme0n1p1 259:1 0 260M 0 part
├─nvme0n1p2 259:2 0 16M 0 part
├─nvme0n1p3 259:3 0 237.2G 0 part
└─nvme0n1p4 259:4 0 1000M 0 part
These I/O errors are probably an indication of a hardware fault, not a software fault, so that’s probably why btrfs ckeck --repair doesn’t work.
You might try running sudo smartctl -x /dev/sda just to see what it says about the state of the physical drive. There probably isn’t much you can do about it if the drive is bad though. The only way to protect all your data from that sort of error is to have redundant (“mirrored”) data partitions on separate physical drives.
=== START OF INFORMATION SECTION ===
Device Model: Intenso SSD Sata III
Serial Number: AA0000000000001158
LU WWN Device Id: 5 000000 000000000
Firmware Version: Q0303B
User Capacity: 506,806,140,928 bytes [506 GB]
Sector Size: 512 bytes logical/physical
Rotation Rate: Solid State Device
Device is: Not in smartctl database [for details use: -P showall]
ATA Version is: ACS-2 (minor revision not indicated)
SATA Version is: SATA 3.1, 6.0 Gb/s (current: 6.0 Gb/s)
Local Time is: Sun Nov 13 10:51:05 2022 UTC
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
AAM feature is: Disabled
APM feature is: Unavailable
Rd look-ahead is: Enabled
Write cache is: Enabled
DSN feature is: Unavailable
ATA Security is: Disabled, NOT FROZEN [SEC1]
Wt Cache Reorder: Unknown
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
General SMART Values:
Offline data collection status: (0x05) Offline data collection activity
was aborted by an interrupting command from host.
Auto Offline Data Collection: Disabled.
Self-test execution status: ( 16) The self-test routine was aborted by
the host.
Total time to complete Offline
data collection: ( 0) seconds.
Offline data collection
capabilities: (0x71) SMART execute Offline immediate.
No Auto Offline data collection support.
Suspend Offline collection upon new
command.
No Offline surface scan supported.
Self-test supported.
Conveyance Self-test supported.
Selective Self-test supported.
SMART capabilities: (0x0002) Does not save SMART data before
entering power-saving mode.
Supports SMART auto save timer.
Error logging capability: (0x01) Error logging supported.
General Purpose Logging supported.
Short self-test routine
recommended polling time: ( 1) minutes.
Extended self-test routine
recommended polling time: ( 1) minutes.
Conveyance self-test routine
recommended polling time: ( 1) minutes.
SCT capabilities: (0x003d) SCT Status supported.
SCT Error Recovery Control supported.
SCT Feature Control supported.
SCT Data Table supported.
SMART Attributes Data Structure revision number: 1
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAGS VALUE WORST THRESH FAIL RAW_VALUE
1 Raw_Read_Error_Rate ------ 100 100 000 - 0
5 Reallocated_Sector_Ct ------ 100 100 000 - 934
9 Power_On_Hours ------ 100 100 000 - 30
12 Power_Cycle_Count ------ 100 100 000 - 245
160 Unknown_Attribute ------ 100 100 000 - 0
161 Unknown_Attribute ------ 100 100 000 - 117
163 Unknown_Attribute ------ 100 100 000 - 42
164 Unknown_Attribute ------ 100 100 000 - 9159
165 Unknown_Attribute ------ 100 100 000 - 23
166 Unknown_Attribute ------ 100 100 000 - 0
167 Unknown_Attribute ------ 100 100 000 - 4
168 Unknown_Attribute ------ 100 100 000 - 3000
169 Unknown_Attribute ------ 100 100 000 - 100
175 Program_Fail_Count_Chip ------ 100 100 000 - 0
176 Erase_Fail_Count_Chip ------ 100 100 000 - 0
177 Wear_Leveling_Count ------ 100 100 050 - 0
178 Used_Rsvd_Blk_Cnt_Chip ------ 100 100 000 - 12
181 Program_Fail_Cnt_Total ------ 100 100 000 - 0
182 Erase_Fail_Count_Total ------ 100 100 000 - 0
192 Power-Off_Retract_Count ------ 100 100 000 - 58
194 Temperature_Celsius ------ 100 100 000 - 31
195 Hardware_ECC_Recovered ------ 100 100 000 - 0
196 Reallocated_Event_Count ------ 100 100 016 - 0
197 Current_Pending_Sector ------ 100 100 000 - 0
198 Offline_Uncorrectable ------ 100 100 000 - 0
199 UDMA_CRC_Error_Count ------ 100 100 050 - 4
232 Available_Reservd_Space ------ 100 100 000 - 90
241 Total_LBAs_Written ------ 100 100 000 - 33478
242 Total_LBAs_Read ------ 100 100 000 - 41341
245 Unknown_Attribute ------ 100 100 000 - 73272
||||||_ K auto-keep
|||||__ C event count
||||___ R error rate
|||____ S speed/performance
||_____ O updated online
|______ P prefailure warning
General Purpose Log Directory Version 1
SMART Log Directory Version 1 [multi-sector log support]
Address Access R/W Size Description
0x00 GPL,SL R/O 1 Log Directory
0x01 GPL,SL R/O 1 Summary SMART error log
0x02 GPL,SL R/O 1 Comprehensive SMART error log
0x03 GPL,SL R/O 1 Ext. Comprehensive SMART error log
0x04 GPL,SL R/O 8 Device Statistics log
0x06 GPL,SL R/O 1 SMART self-test log
0x07 GPL,SL R/O 1 Extended self-test log
0x09 GPL,SL R/W 1 Selective self-test log
0x10 GPL,SL R/O 1 NCQ Command Error log
0x11 GPL,SL R/O 1 SATA Phy Event Counters log
0x30 GPL,SL R/O 9 IDENTIFY DEVICE data log
0x80-0x9f GPL,SL R/W 16 Host vendor specific log
0xe0 GPL,SL R/W 1 SCT Command/Status
0xe1 GPL,SL R/W 1 SCT Data Transfer
SMART Extended Comprehensive Error Log Version: 1 (1 sectors)
No Errors Logged
SMART Extended Self-test Log Version: 1 (1 sectors)
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Abort offline test Completed without error 00% 30 -
# 2 Short offline Self-test routine in progress 90% 30 -
SMART Selective self-test log data structure revision number 1
SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS
1 0 0 Not_testing
2 0 0 Not_testing
3 0 0 Not_testing
4 0 0 Not_testing
5 0 0 Not_testing
6 0 65535 Read_scanning was aborted by an interrupting command from host
Selective self-test flags (0x0):
After scanning selected spans, do NOT read-scan remainder of disk.
If Selective self-test is pending on power-up, resume after 0 minute delay.
SCT Status Version: 3
SCT Version (vendor specific): 0 (0x0000)
Device State: Active (0)
Current Temperature: 0 Celsius
Power Cycle Min/Max Temperature: 127/ 0 Celsius
Lifetime Min/Max Temperature: 0/47 Celsius
Under/Over Temperature Limit Count: 0/0
SCT Temperature History Version: 2
Temperature Sampling Period: 1 minute
Temperature Logging Interval: 1 minute
Min/Max recommended Temperature: 0/100 Celsius
Min/Max Temperature Limit: 0/100 Celsius
Temperature History Size (Index): 128 (77)
Index Estimated Time Temperature Celsius
78 2022-11-13 08:44 ? -
... ..(126 skipped). .. -
77 2022-11-13 10:51 ? -
SCT Error Recovery Control:
Read: Disabled
Write: Disabled
Device Statistics (GP Log 0x04)
Page Offset Size Value Flags Description
0x01 ===== = = === == General Statistics (rev 2) ==
0x01 0x008 4 245 --- Lifetime Power-On Resets
0x01 0x010 4 30 --- Power-on Hours
0x01 0x018 6 2194029226 --- Logical Sectors Written
0x01 0x020 6 10469903 --- Number of Write Commands
0x01 0x028 6 2709347174 --- Logical Sectors Read
0x01 0x030 6 13399606 --- Number of Read Commands
0x02 ===== = = === == Free-Fall Statistics (empty) ==
0x03 ===== = = === == Rotating Media Statistics (empty) ==
0x04 ===== = = === == General Errors Statistics (rev 1) ==
0x04 0x008 4 0 --- Number of Reported Uncorrectable Errors
0x04 0x010 4 60 --- Resets Between Cmd Acceptance and Completion
0x05 ===== = = === == Temperature Statistics (empty) ==
0x06 ===== = = === == Transport Statistics (rev 1) ==
0x06 0x008 4 7190 --- Number of Hardware Resets
0x06 0x018 4 4 --- Number of Interface CRC Errors
0x07 ===== = = === == Solid State Device Statistics (rev 1) ==
0x07 0x008 1 0 --- Percentage Used Endurance Indicator
|||_ C monitored condition met
||__ D supports DSN
|___ N normalized value
Pending Defects log (GP Log 0x0c) not supported
SATA Phy Event Counters (GP Log 0x11)
ID Size Value Description
0x0001 2 0 Command failed due to ICRC error
0x0002 2 0 R_ERR response for data FIS
0x0003 2 0 R_ERR response for device-to-host data FIS
0x0004 2 0 R_ERR response for host-to-device data FIS
0x0005 2 0 R_ERR response for non-data FIS
0x0006 2 0 R_ERR response for device-to-host non-data FIS
0x0007 2 0 R_ERR response for host-to-device non-data FIS
0x0008 2 0 Device-to-host non-data FIS retries
0x0009 2 0 Transition from drive PhyRdy to drive PhyNRdy
0x000a 2 2 Device-to-host register FISes sent due to a COMRESET
0x000b 2 0 CRC errors within host-to-device FIS
0x000d 2 0 Non-CRC errors within host-to-device FIS
0x000f 2 0 R_ERR response for host-to-device data FIS, CRC
0x0010 2 0 R_ERR response for host-to-device data FIS, non-CRC
0x0012 2 0 R_ERR response for host-to-device non-data FIS, CRC
0x0013 2 0 R_ERR response for host-to-device non-data FIS, non-CRC
The 934 bad sectors were there the day I purchased the drive. This should not be the problem, right?. The drive also passes the smart test, so should I just format it and re-render my fractals? I found an sd card with my photos. The only file I can’t get back is a Python script I wrote.
That is good. Now that you don’t have much to lose, format your disk. Always keep in mind that you should keep at least a copy of any important data you have.
After this command I installed Zorine OS (sorry for the lack of fidelity to fedora…). The install proceeded smoothly. After installing, no errors. The SMART data didn’t change. I ran a few disk checking tools and all of them said 100% health.
Truth is, the problem occured when I left my old PC on (was testing ddr3 sticks), went dining, and came back. The PC went to sleep. I thought I had turned it off. Then I proceeded to add a stick of RAM (still though it was off). I managed to put the ram stick backwards! It didn’t fully insert but shorted something. The computer instantly turned off. The SSD was connected via a USB adapter. Surprisingly the RAM still worked. Maybe this made the data controller think it got a write operation for a block right at the beginning of the partition? All of the other partitions were still readable.
And why would it destroy disks? Running it for a second overwrites the MBR/GPT and running it until completion performs a full wipe? It can’t render a SSD unusable?
There is absolutely no telling what kind of data corruption might have occurred in that case. If the hardware was truly OK though, I am surprised that Btrfs’ repair command couldn’t recover the filesystem. It might have just taken some sort of more aggressive repair options to get it to revert to a “last known good” state. I know zfs has some recovery options like that. But I’m not that familiar with Btrfs.
BTW, you should definitely do a full memory test to be sure. Sometimes RAM can seem to work OK, but it only seems that way because it hasn’t accessed any of the bad memory addresses yet. So things work OK until one day when you start up that image processing software or whatever that causes some higher memory addresses to be accessed and then …
The last ~160 kb of RAM on that stick is corrupted. However, as I never do anything important on that computer (except testing sus USB sticks) I will keep the ram. I use my laptop for anything else, R3 5300U vs Intel Core i7 2600 on the desktop is not a fair fight
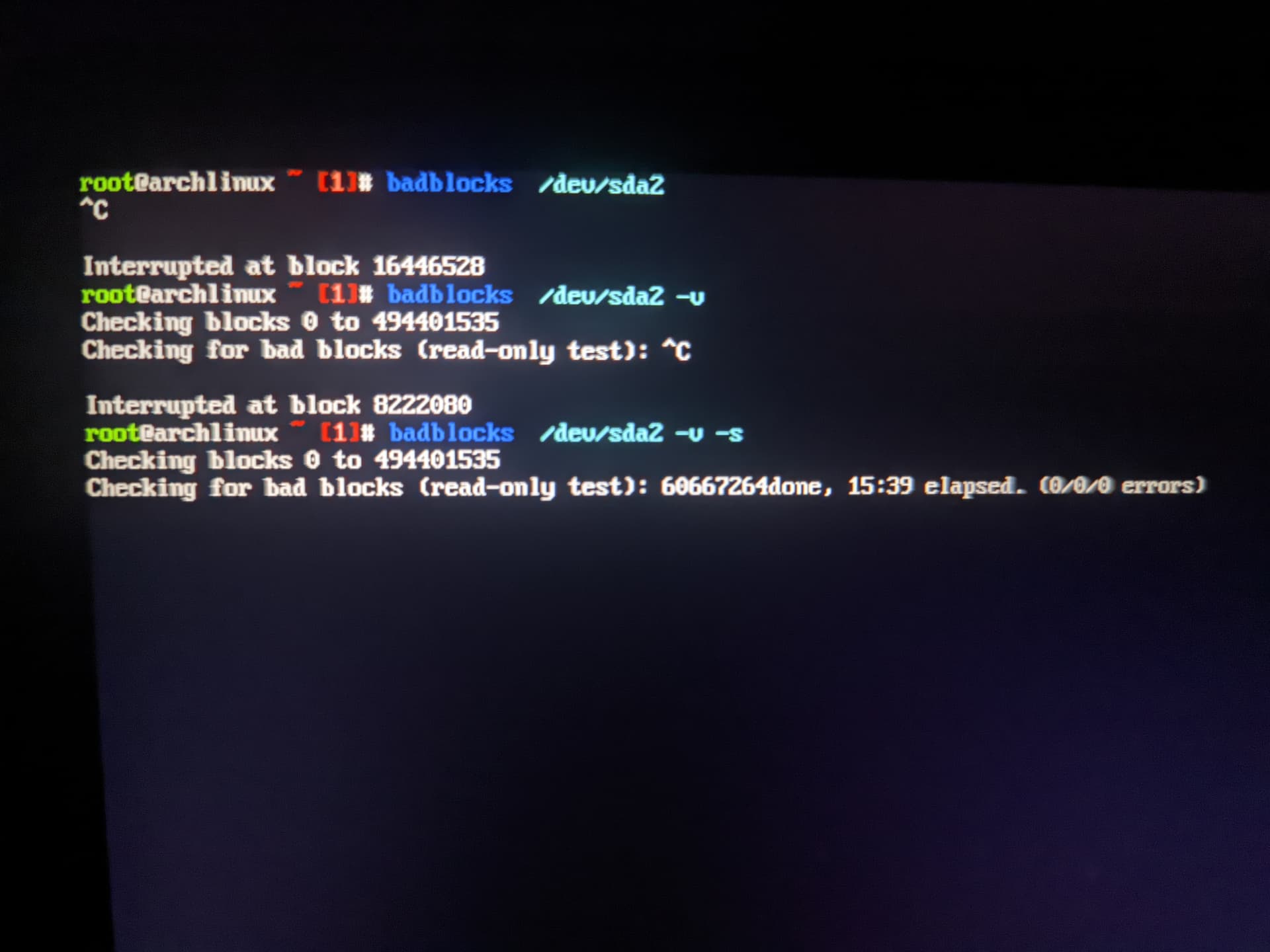
UPDATE: I have broken both Zorin and Manjaro (I’m a distro hopper and a pro distro breaker) by installing too many themes and creating a dependency hell… I now have installed Arch without a script (it was tedious) so I don’t expect to break it anytime soon. The good news is that the disk still seems fine!
Apparently no bad blocks, which is very surprising.
Oh and I forgot: on Manjaro and Zorin, I had multiple package managers (apt, DNF and pacman at the same time), Cinnamon, Gnome, and KDE, and the worse part: GDM, lightdm and Sway, that I have all set to be the login manager in their respective.conf files, and then enabled them with systemctl. This made broken symlinks pointing to garbage addresses… You see where that’s going
I just wanted to see how many conflicting packages I could install before the system breaks down. The answer is not many.
In that video from FlyTech, a fat32 filesystem is edited to put slashes in filenames. The result is an I/O error if la is used in the directory, which could explain brefs check failing.
I installed some binaries manually and some dependencies from apt/pacman. The internet tells me it’s a recipe for disaster. I wanted disaster. It worked perfectly! (As a hell simulator not as a functional system)
You cannot mount the btrfs volume, but need to specify the subvolume with a mount command similar to what is seen in /etc/fstab. mount -t btrfs -o subvol=root,compress=zstd:1 UUID /mnt/p5 or something similar.
Note the use of both file system type and options in that command.
for context, that command would definitely work if i hadn’t messed up nvme0n1p5 partition, yes, i did manually (and unfortunately) mess it up when trying to resize (shrink) it down using gparted in a live environment booted from a usb flash drive;
what i know now from reading dmesg logs is that btrfs nvme0n1p5 partition should be 96636764160 bytes in size (about 90gib and is the amount i wanted to shrink down to) but the system read it at 157838999552 bytes (about 147gib which is its original size) so due to this error i cannot mount it, and as far as i know in order to resize it back to 147gib it needs to be mounted but again i cannot mount it to resize it, it’s an infinite loop @@