Background
The top-level issue is that my box gets these ongoing messages in its log:
Oct 31 03:24:39 example.com kernel: BTRFS info (device sda2): bdev /dev/sda2 errs: wr 0, rd 0, flush 0, corrupt 192, gen 0
This system has two drives with btrfs on sda2 and sdb2.
Earlier some things that I did:
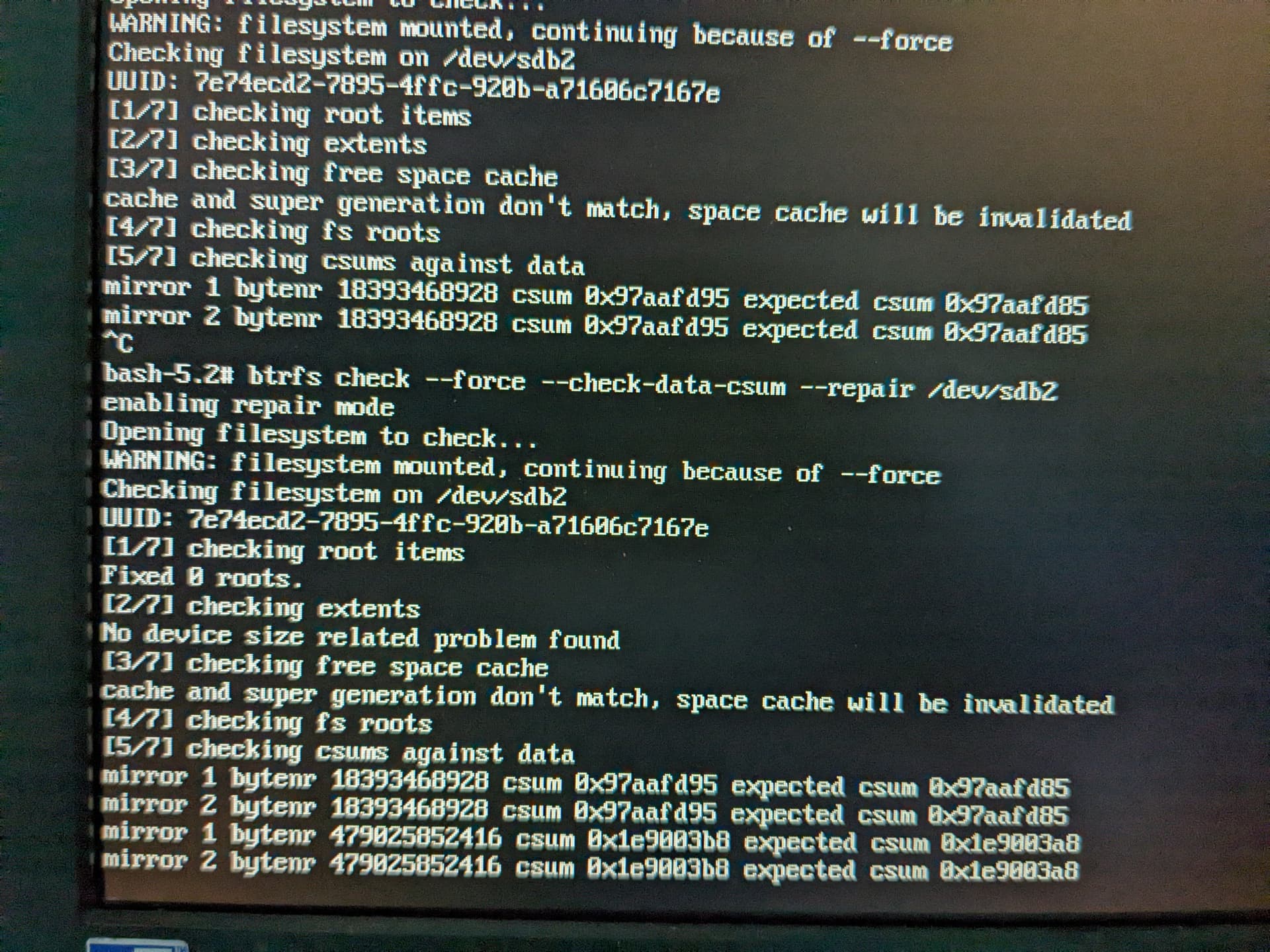
Screenshot shows an attempt to correct in “single init=/bin/bash” mode with “btrfs check”.
Ultimately correction required translating bytenr values into files. I switched to a LiveCD environment.
In order for btrfs inspect-internal logical-resolve to output the path names of the files which contained blocks that had issues I had to mount the subvols that contained the files that the bytenr values corresponded to. That command will not output any path names if you just mount an arbitrary part of the btrfs. I deleted the files at the ends of the path names which were reported.
I ran btrfs scrub and no errors were reported. I ran a full btrfs balance largely because this downtime provided a good opportunity. It took maybe 3 to 6 hours to complete. Neither of those commands output any error messages on stdout/stderr to the terminal. In the journal there are still errors, see the beginning of this post.
Root cause analysis: the csum values “expected” and “actual” differ only by one bit (see screenshot above). Specifically, 0x97aafd95 and 0x97aafd85 have only one bit which differs. I think there are really RAM issues not SDD ones. This computer’s mobo has a long history of RAM problems.
The kernel documentation and code suggests that BTRFS_DEV_STAT_CORRUPTION_ERRS is not a direct I/O failure as in “didn’t get EIO” from a driver.
Is there some way to repair the “corrupt 192” situation?
Oct 31 03:24:39 example.com kernel: BTRFS info (device sda2): bdev /dev/sda2 errs: wr 0, rd 0, flush 0, corrupt 192, gen 0
Kernel Code Details
https://btrfs.wiki.kernel.org/index.php/Data_Structures
The codes below indicate an indirect I/O failure:
BTRFS_DEV_STAT_CORRUPTION_ERRS 0x4
checksum error, bytenr error or contents is illegal: this is an indication that the block was damaged during read or write, or written to wrong location or read from wrong location
Functions that increment the BTRFS_DEV_STAT_CORRUPTION_ERRS value:
linux/fs/btrfs/volumes.c
void btrfs_dev_stat_inc_and_print(struct btrfs_device *dev, int index)
{
btrfs_dev_stat_inc(dev, index);
if (!dev->dev_stats_valid)
return;
btrfs_err_rl_in_rcu(dev->fs_info,
"bdev %s errs: wr %u, rd %u, flush %u, corrupt %u, gen %u",
rcu_str_deref(dev->name),
btrfs_dev_stat_read(dev, BTRFS_DEV_STAT_WRITE_ERRS),
btrfs_dev_stat_read(dev, BTRFS_DEV_STAT_READ_ERRS),
btrfs_dev_stat_read(dev, BTRFS_DEV_STAT_FLUSH_ERRS),
btrfs_dev_stat_read(dev, BTRFS_DEV_STAT_CORRUPTION_ERRS),
btrfs_dev_stat_read(dev, BTRFS_DEV_STAT_GENERATION_ERRS));
}
linux/fs/btrfs/volumes.h
static inline void btrfs_dev_stat_inc(struct btrfs_device *dev,
int index)
{
atomic_inc(dev->dev_stat_values + index);
/*
* This memory barrier orders stores updating statistics before stores
* updating dev_stats_ccnt.
*
* It pairs with smp_rmb() in btrfs_run_dev_stats().
*/
smp_mb__before_atomic();
atomic_inc(&dev->dev_stats_ccnt);
}